
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 스택
- 그래프 탐색
- DP
- 자바스크립트
- 그래프 이론
- 프로그래머스
- 오라클
- Python
- 문자열
- 완전탐색
- BFS
- 깊이우선탐색
- oracle
- 다이나믹 프로그래밍
- 브루트포스 알고리즘
- 데이터베이스
- SWEA
- 브루트포스
- 너비 우선 탐색
- 그리디 알고리즘
- 백준알고리즘
- 다익스트라
- 너비우선탐색
- 파이썬
- 백준 알고리즘
- SW Expert Academy
- DFS
- 구현
- 백트래킹
- javascript
- Today
- Total
민규의 흔적
[오라클 DB] 파일 조직 - 히프 파일, 순차 파일 본문
File을 파일 또는 화일이라고 읽는데, 여기서는 파일로 읽겠다.
파일(File) 조직의 유형
- 히프 파일(Heap File)
- 순차 파일(Sequential File)
- 인덱스된 순차 파일(Indexed Sequential File)
- 직접 파일(Hash File)
히프 파일(비순서 파일)
가장 단순한 파일 조직으로, 레코드들이 삽입된 순서대로 파일에 저장된다.
정렬되어있지 않으며, 맨 마지막에 저장된 레코드는 맨 마지막에 저장되는 방식이다.
삽입 : 새로 삽입되는 레코드는 파일의 가장 끝에 첨부됨(빠름)
검색 : 원하는 레코드를 찾기 위해서는 모든 레코드들을 순차적으로 접근해야 함(모든 레코드를 검색하지 않는다면 느림)
삭제 : 원하는 레코드를 찾은 후에 그 레코드를 삭제하고, 삭제된 레코드가 차지하던 공간을 재사용하지 않음(느림)
좋은 성능을 유지하기 위해서는 히프 파일을 주기적으로 재조직할 필요가 있다.
릴레이션에 데이터를 한꺼번에 적재할 때(Bulk Loading), 또는 릴레이션에 몇 개의 블록들만 있을 경우 검색 위주로 사용될 때 주로 사용한다.
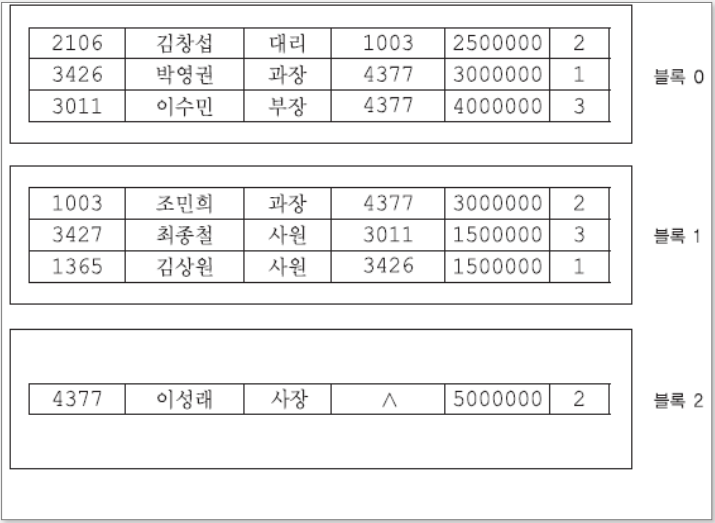
위 히프 파일 예시에서 볼 수 있듯이, 레코드가 삽입된 순서대로 적재되며 정렬되어있지 않은 모습을 보인다.
히프 파일의 성능
히프 파일은 질의에서 모든 레코들을 참조하고, 레코드들을 접근하는 순서가 중요하지 않을 경우에는 유용하다.
예를 들면 다음과 같은 경우이다.
SELECT *
FROM EMPLOYEE;
모든 레코드를 읽어오는 것이라 정렬되어있나 정렬되어있지않나 차이가 없다.
하지만 아래와 같이 특정 레코드를 검색하는 경우에는 히프 파일이 비효율적이다.
SELECT TITLE
FROM EMPLOYEE
WHERE EMPNO = 1365;
WHERE절의 EMPNO가 유니크하다고 가정했을 때, 그리고 레코드 개수가 N이라고 가정했을때 원하는 데이터를 얻기 위한 검색 횟수는 최소 1번(한 번에 찾는 경우), 최대 N번(모든 레코드들을 조회해보는 경우)이다.
평균적으로 N/2개의 블록을 읽어야 한다는 소리이다.
하지만 EMPNO가 유니크하지 않다고 가정했을 때에는 모든 레코드를 읽어보며 EMPNO가 1365인 레코드들을 찾아야하기 때문에, 무조건 N개의 블록을 모두 읽어야 한다.
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE DNO = 2;
위의 경우 또한, DNO가 유니크하지 않은 속성이므로 조건에 맞는 레코드를 이미 한 개 이상 검색했더라도 파일 마지막 블록까지 읽어서 원하는 레코드가 존재하는가를 확인해야 하기 때문에 N개의 블록을 모두 읽어야 한다.
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 4000000;
급여의 범위를 만족하는 레코드들을 모두 검색하는 위의 질의 또한 EMPLOYEE 릴레이션의 모든 레코드들을 접근해야 한다. 따라서 N개의 블록을 모두 읽어야 한다.
| 연산의 유형 | 시간 |
| 삽입 | 효율적 |
| 삭제 | 시간이 많이 소요 |
| 탐색 | 시간이 많이 소요 |
| 순서대로 검색 | 시간이 많이 소요 |
| 특정 레코드 검색 | 시간이 많이 소요 |
요즘은 하드웨어 성능이 좋아, 블록의 개수가 10만개 이하라면 히프 파일 검색속도도 드라마틱하게 느리다고 체감되지 않는다. (하지만 다른 파일 조직에 비하면 느린 것이 맞다.)
히프 파일 성능 예시
가정
파일에 레코드가 10,000,000개 있고, 각 레코드의 길이가 200바이트이고, 블록 크기가 4,096 바이트이면 블록킹 인수는 ⌊ 4,096 / 200 ⌋ = 20인 파일을 가정해보자.
여기서, 블록킹 인수(Blocking Factor)는 한 블록에 포함되는 레코드 수를 의미한다.
블록킹 인수는 레코드의 크기에 따라 달라진다.
이 파일을 위해 필요한 총 블록 수는 ⌈ 10,000,000 / 20 ⌉ = 500,000이다.
특정 레코드를 찾기 위해서는평균적으로 500,000 / 2 = 250,000개의 디스크 블록을 읽어야 한다.
한 블록일 읽는데 10ms가 걸린다고 가정하면 250,000 X 10ms = 2,500,000ms = 2,500초, 약 42분이 소요된다.
순차 파일
레코드들이 하나 이상의 필드 값에 따라 순서대로 저장된 파일을 뜻하며, 기본적으로 기본 키를 기준으로 정렬되어있다.
레코드의 탐색 키(Search Key) 값의 순서에 따라 저장되며, 탐색 키는 순차 파일을 저장하는데 사용되는 필드를 의미한다.
만약 이름을 기준으로 탐색하려면 따로 파일을 빼서 정렬하여 새로운 인덱스를 생성한다.
삽입 연산은 삽입하려는 레코드의 순서를 고려해야 하기 때문에 시간이 많이 걸릴 수 있고, 삭제 연산은 삭제된 레코드가 사용하던 공간을 빈 공간으로 남기기 때문에 히프 파일의 경우와 마찬가지로 주기적으로 순차 파일을 재조직해야 한다.
하지만 검색을 사용하는 케이스가 많다보니 전체적으로는 효율적이라고 볼 수 있다.
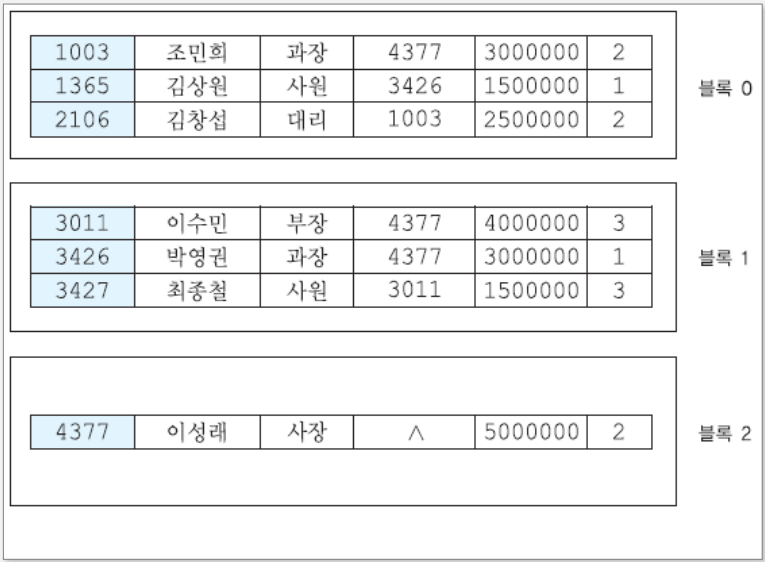
위 순차 파일 예시에서 볼 수 있듯이, 기본 키인 EMPNO를 기준으로 정렬되어 있는 모습을 볼 수 있다.
여기서는 탐색 키가 기본 키인 것이다.
순차 파일의 성능
EMPLOYEE 파일이 EMPNO(기본 키)의 순서대로 저장되어 있다고 가정하겠다.
Case 1.
SELECT TITLE
FROM EMPLOYE
WHERE EMPNO = 1365;
Case 1은 WHERE절에 조건식이 EMPNO의 특정 값을 찾도록 제시되어있기 때문에 이미 정렬되어 있는 기본 키인 EMPNO 애트리뷰트의 특정 값을 찾아내면 된다.
이미 정렬되어 있기에 이진 탐색(Binary Search) 기법을 사용하면 log2(N) 시간 안에 원하는 값을 찾을 수 있다.
Case 2.
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 4000000;
Case 2의 WHERE 절에 조건식이 특정 SALARY 범위 안에 만족하는 값을 찾도록 제시되어 있다.
SALARY는 정렬되어 있지 않은 속성이기에 결국 모두 탐색해야 하므로 N번 검색해야 한다.
| 연산의 유형 | 시간 |
| 삽입 | 시간이 많이 소요 |
| 삭제 | 시간이 많이 소요 |
| 탐색 키를 기반으로 탐색 | 효율적 |
| 탐색 키가 아닌 필드를 사용하여 검색 | 시간이 많이 소요 |
순차 파일 성능 예시
가정
파일에 레코드가 10,000,000개 있고, 각 레코드의 길이가 200바이트이고, 블록 크기가 4,096 바이트이면 블록킹 인수는 ⌊ 4,096 / 200 ⌋ = 20인 파일을 가정해보자.
이 가정 값들은 위 히프 파일 성능 예시의 값들과 같다.
이진 탐색을 한다면 ⌈ log2(500,000) ⌉ = 19개의 블록을 읽어야 하고,
이에 필요한 시간은 19 X 10ms = 190ms이다.
히프 파일에서 소요된 시간 2,500,000ms과 비교해서 1 / 13,158 밖에 안 걸린다. (정렬과 비정렬의 차이)
이 레코드 이후의 레코드들을 차례대로 검색하는 경우에는 연속된 레코드들이 저장된 블록들을 물리적으로 인접한 블록들에 저장함으로써 탐구 시간을 최소화할 수 있다.
'데이터베이스' 카테고리의 다른 글
| [오라클 DB] 다단계 인덱스 (2) | 2023.11.20 |
|---|---|
| [오라클 DB] 파일 조직 - 인덱스된 순차 파일, 단일 단계 인덱스 (2) | 2023.11.14 |
| [오라클 DB] 릴레이션 분해와 정규형(Normal Form) (2) | 2023.11.01 |
| [오라클 DB] 릴레이션 분해와 결정자, 함수적 종속성 (2) | 2023.11.01 |
| [오라클 DB] 정규화와 갱신 이상(update anomaly) (0) | 2023.10.31 |



