
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 파이썬
- 브루트포스
- 그래프 이론
- SWEA
- 오라클
- Python
- 문자열
- 스택
- 다이나믹 프로그래밍
- 깊이우선탐색
- 구현
- 백트래킹
- oracle
- 그리디 알고리즘
- 데이터베이스
- 너비우선탐색
- 프로그래머스
- BFS
- 다익스트라
- 너비 우선 탐색
- 브루트포스 알고리즘
- javascript
- SW Expert Academy
- DFS
- 완전탐색
- DP
- 자바스크립트
- 그래프 탐색
- 백준알고리즘
- 백준 알고리즘
- Today
- Total
민규의 흔적
[알고리즘] 패턴 매칭 알고리즘, KMP 알고리즘 ( Knuth–Morris–Pratt Algorithm ) 본문
오탈자나 오류를 범한 내용이 있다면 댓글 남겨주세요!! 언제든 환영합니다!!!!!
2024년 10월 10일
패턴 매칭
당장 ctrl + F를 누르면 현재 페이지에서 찾고자 하는 키워드를 손쉽게 찾을 수 있는 기능이 존재한다.
이와 같이 전체 문자열에서 특정 키워드(패턴)을 찾는 것을 패턴 매칭이라고 부른다.
패턴 매칭 알고리즘
문자열 패턴 매칭 알고리즘은 워드패드, 논문, 웹 페이지 등에서 원하는 키워드를 검색할 때 빠른 속도로 찾게 해주는 중요한 역할을 한다.
문서 전체의 길이가 길수록, 그리고 검색하려는 키워드(패턴)의 길이가 길수록 효율적인 패턴 매칭 알고리즘을 필요로 하게 된다.
패턴 매칭 알고리즘에는 여러 가지가 존재하지만, 이 글에선 브루트포스( brute force ) 방식과 KMP 알고리즘 방식을 비교하며 설명하고자 한다.
브루트포스( brute force )
완전 탐색을 통해 무식(?)하게 찾는 방법이다.
전체 문자열과 패턴이 다음과 같다고 가정해보겠다.
전체 문자열 : abceabcdabcwabcdabcxabcdabcf
패턴 : abcdabcx
이제 패턴을 맨 앞에서부터(혹은 맨 뒤에서부터) 차례대로 패턴과 일치하는지 확인한다.

패턴과 일부 일치했지만 3번째 인덱스 값인 d에서 불일치가 일어났다. 그러므로 다음과 같이 비교하는 첫 인덱스를 한 칸 미뤄 비교를 진행한다.


한 칸씩 인덱스를 옮겨보다 패턴과 일치하는 문자열의 일부가 식별되면 패턴의 마지막 인덱스까지 매칭되는지 체크한다.
하지만 마지막 인덱스에서 아쉽게 불일치가 일어나는 모습이다.
(중간 생략)

위 과정을 반복하다보니 12번째 인덱스 지점에서부터 패턴의 마지막 인덱스까지 매칭되는 부분 문자열을 발견했다.
이러한 방식으로 전체 문자열의 처음부터 끝까지 순차적으로 순회해보며 패턴과 일치하는 부분이 어디에 존재하는지 확인하는 방식이 브루트포스 방식이다.
위 방식을 Python 코드로 작성하면 다음과 같다.
Python 코드 ( 브루트포스 )
# brute force
def pattern_matching(word, pattern):
# 패턴에서 현재 비교할 인덱스 번호
p_idx = 0
# 전체 문자열에서 현재 비교중인 인덱스 번호
w_idx = 0
word_length = len(word)
pattern_length = len(pattern)
# 패턴이 매칭된 횟수
matched_cnt = 0
# 패턴이 매칭되기 시작한 포인트(인덱스)
matched_point = []
for idx in range(word_length - pattern_length + 1):
w_idx = idx
# 전체 문자열의 현재 인덱스 요소부터 패턴과 매칭되는지 확인
while word[w_idx] == pattern[p_idx]:
# 패턴의 마지막 요소까지 일치했다면 매칭된 개수를 1 증가시키고 매칭이 시작된 시작점을 append
if p_idx == pattern_length - 1:
matched_cnt += 1
matched_point.append(idx)
break
w_idx += 1
p_idx += 1
# 매칭 확인이 끝났으므로 패턴에서 비교할 인덱스 번호를 0으로 초기화
p_idx = 0
print(matched_cnt)
print(matched_point)
if __name__ == "__main__":
word = "abceabcdabcwabcdabcxabcdabcf"
pattern = "abcdabcx"
pattern_matching(word, pattern)
브루트포스 방식의 시간 복잡도
전체 문자열이 aaaaaaaaaa이고, 패턴이 aaaab라면 패턴의 시작 부분이 전체 문자열의 모든 부분에서 일치가 일어나 패턴의 마지막까지 매칭 여부를 확인하지만 결국 매번 패턴의 마지막에서 불일치가 일어난다.
전체 문자열의 길이가 N이고 패턴의 길이가 M이라면 최악의 경우 전체 문자열 길이 만큼 패턴의 첫 인덱스 부분과 일치하는지 확인( O(N) )하고, 그럴 때마다 패턴의 마지막까지 매칭이 되는지 확인( O(M) )하기에 시간복잡도는 O(N * M)이라고 할 수 있다.
KMP( Knuth–Morris–Pratt ) 알고리즘
KMP 알고리즘은 시간 복잡도 O(N + M)의 매우 효율적인 패턴 매칭 알고리즘이다.
KMP 알고리즘에 대해 이해하기 전 접두사와 접미사의 정의와 LPS 알고리즘 2가지 사전 지식이 필요하다.
이유는 LPS 알고리즘으로 도출된 파이(pi) 배열을 활용해, 불일치가 감지되었을 때 불필요한 비교를 건너뛰기 위함이다.
1. 접두사(prefix)와 접미사(suffix)
접두사와 접미사 개념은 문자열 KOREA를 예로 들면 다음과 같다.
| 길이 | 접두사 | 접미사 |
| 1 | K | A |
| 2 | KO | EA |
| 3 | KOR | REA |
| 4 | KORE | OREA |
| 5 | KOREA | KOREA |
2. LPS 알고리즘
LPS란 Longest Prefix which is also Suffix의 줄임말로, 주어진 문자열의 부분 문자열들 중 가장 긴 접두사이자 접미사를 의미한다.
KMP 알고리즘에서는 패턴의 0번째 인덱스가 무조건 포함되는 부분 문자열들의 LPS 길이가 활용되며, LPS를 구하는 과정에서 overlapping(접두사와 접미사가 겹치는 경우를 포함) 규칙을 적용함을 전제로 한다.
문자열 ababcaba를 예로 들면 다음과 같다.
(접두사와 접미사가 부분 문자열과 일치하는 경우는 포함하지 않는다.)
| Index | 문자열 | LPS |
| 0 | a | 0 |
| 1 | ab | 0 |
| 2 | aba | 1 |
| 3 | abab | 2 |
| 4 | ababc | 0 |
| 5 | ababca | 1 |
| 6 | ababcab | 2 |
| 7 | ababcaba | 3 |
pi = [0, 0, 1, 2, 0, 1, 2, 3]
pi 배열을 구하는 Python 코드는 다음과 같다.
# create pi array by LPS
def create_pi(pattern):
pattern_length = len(pattern)
pi = [0 for _ in range(pattern_length)]
j = 0
for i in range(1, pattern_length):
while j > 0 and pattern[i] != pattern[j]:
j = pi[j - 1]
if pattern[i] == pattern[j]:
j += 1
pi[i] = j
return pi
그림과 함께 코드의 로직을 이해해보자.
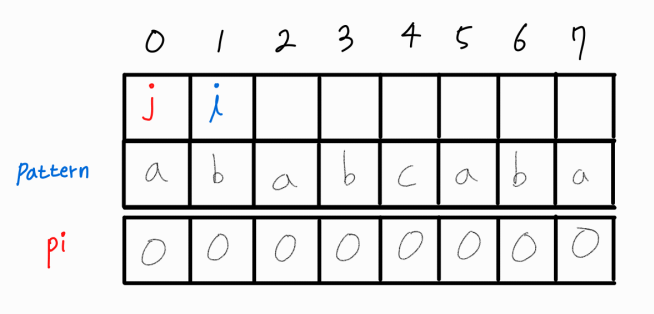
문자열의 길이와 같은 1차원 배열 pi를 선언하고 모든 값은 0으로 초기화 시켜준다.
pi의 n번째 인덱스 요소는 문자열의 0번째 인덱스부터 n번째 인덱스까지의 부분 문자열에서 LPS 길이를 의미한다.
i와 j 인덱스의 의미는 다음과 같다고 이해하면 편하다.
i : 현재 부분 문자열에서 접미사의 가장 마지막 인덱스
j : 현재 부분 문자열에서 접두사와 접미사가 현재 같다고 가정했을 때 접두사의 마지막 인덱스
i와 j가 만약 같다면, i를 1 만큼 증가시켜 다음 부분 문자열의 접두사와 접미사를 비교해볼 때 j 또한 1 증가시켜 접두사 또한 길이를 1 증가시켰을 때 또한 동일한지 확인한다.
만약 다르다면 j는 pi[ j -1 ] 값으로 변경한다.
i와 j가 같을 때 1씩 함께 증가시키는건 어찌저찌 이해하겠는데.. j는 왜 pi[ j - 1 ] 값으로 변경하는거지? 싶을 수 있다.(내가 그랬다.)
이는 뒤에서 자세히 설명하도록 하겠다.
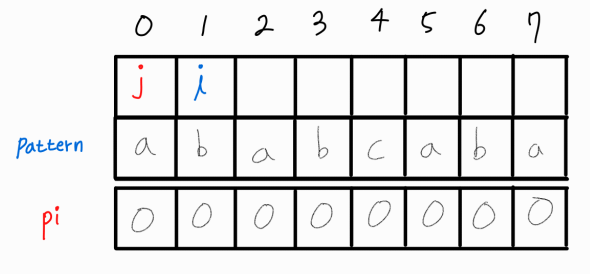
i와 j가 같지 않으므로 해당 부분 문자열에서 LPS의 길이는 0이다.
i만 1 증가시켜준다.
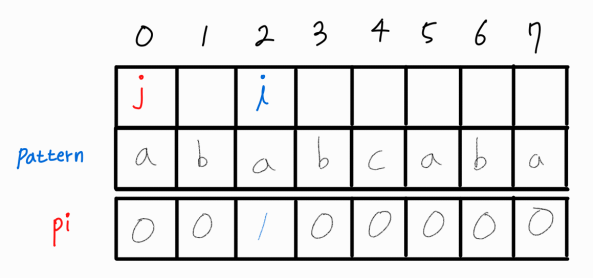
i와 j가 같으므로 해당 부분 문자열에서 LPS의 길이는 1이다.
i와 j 모두 1씩 증가시켜준다.
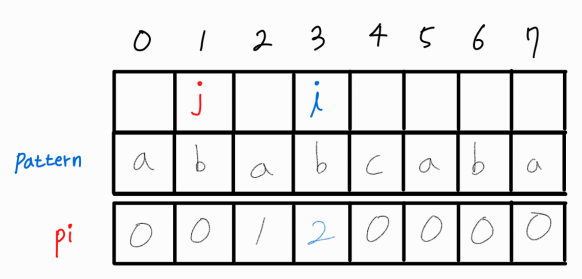
i와 j가 같으므로 해당 부분 문자열에서 LPS의 길이는 2이다. 이는 현재 j 인덱스 까지의 접두사 길이 만큼 접미사 또한 같은 상태라는 의미이다.
여기서 i와 j가 일치했을 때 pi[ i ]의 값에 대한 점화식을 알 수 있다.
만약 pattern[ i ] == pattern[ j ] 라면,
pi[ i ] = j + 1
i와 j 모두 1씩 증가시켜준다.
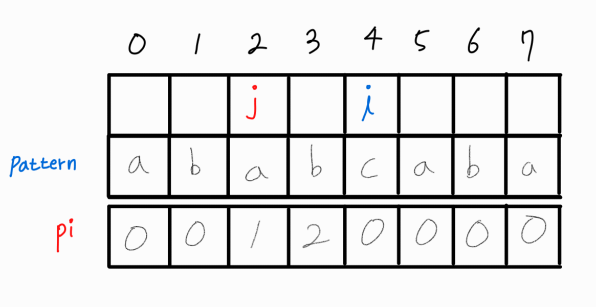
i와 j가 같지 않기에 j를 pi[ j - 1 ]인 0으로 변경시켜준다.
j를 바꾼 후에도 i와 j는 같지 않기에 해당 부분 문자열에서 LPS 길이는 0이다.
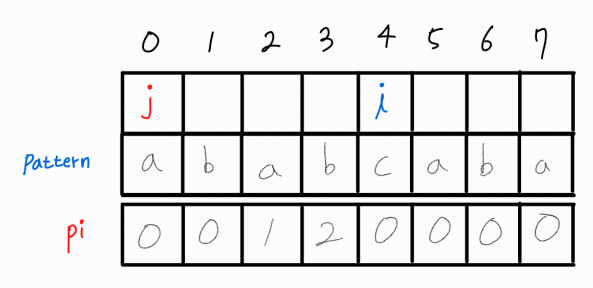
이후 i를 1 증가시킨다.
i와 j가 같으므로 해당 부분 문자열의 LPS 길이는 1이다.
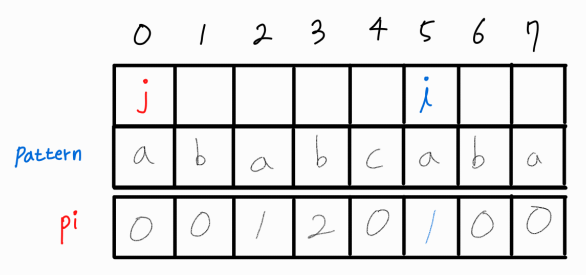
i와 j를 모두 1씩 증가시켜준다.
i와 j가 같으므로 해당 부분 문자열의 LPS 길이는 2이다.
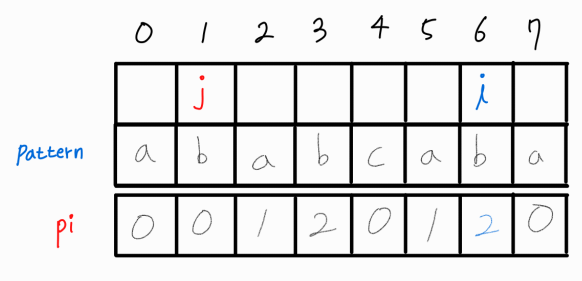
i와 j를 모두 1씩 증가시켜준다.
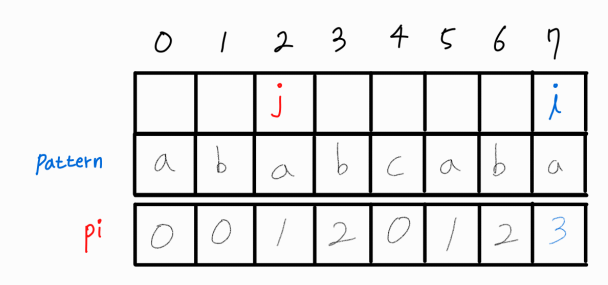
i와 j가 같으므로 해당 부분 문자열의 LPS 길이는 3이다.
전체 문자열의 마지막 인덱스에서의 비교가 끝났으므로 로직을 마무리한다.
※ 어째서 pattern[ i ] != pattern[ j ]라면 j = pi[ j - 1 ] 인가?!
전체 문자열의 i번째 인덱스와 j번째 인덱스 요소가 다르다면 j의 위치를 이동시켜주어야 한다.
그러면 j는 어디로 이동시켜주어야 할까?
다음의 예시를 보자.
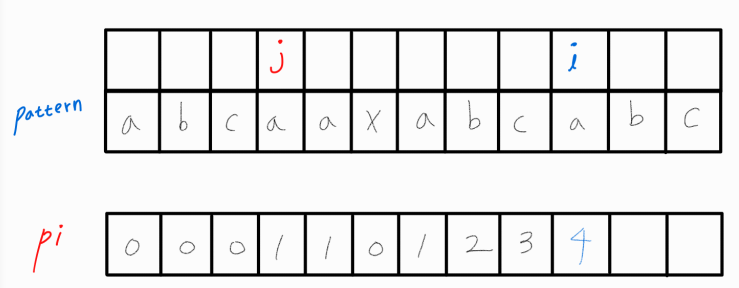
현재 i와 j가 같기에 pi[ i ] 에 j + 1 값을 삽입한 상황이다.
i와 j가 같으므로 둘 다 1씩 증가시켜준다.
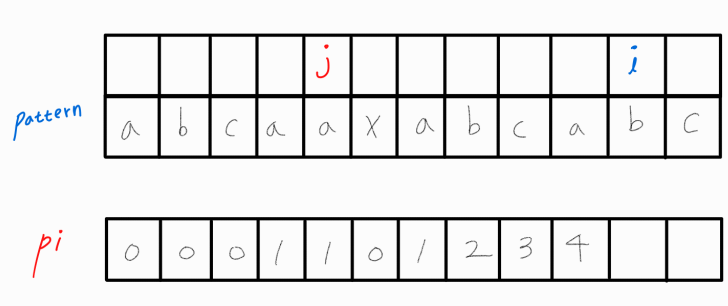
i와 j가 다르기에 LPS의 길이가 5인 경우는 물건너갔다.
그러므로 j의 위치를 바꿔주어야 하는데, 무작정 j를 0번째 인덱스로 옮겨버리면 오류를 범하게 된다.
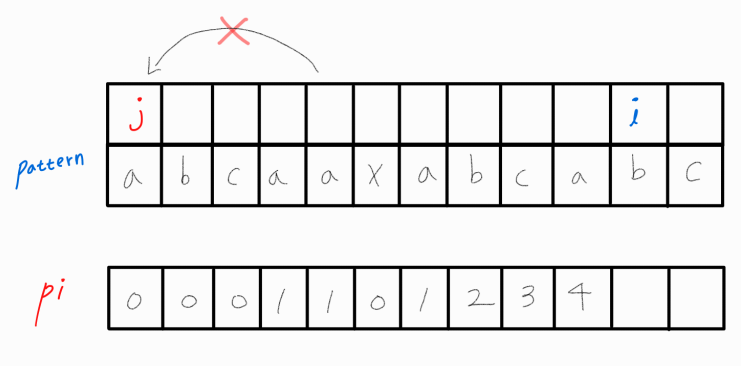
실제로 abcaaxabcab의 LPS 길이는 2이므로, j를 0으로 옮겨버리면 pattern[ i ] != pattern[ j ]이므로 pi[ i ] = 0이 삽입되게 된다.
그렇다면 j는 어디로 옮겨봐야 할까??
여기서 위 pi 배열을 해석하면 아래와 같이 나타낼 수 있다.
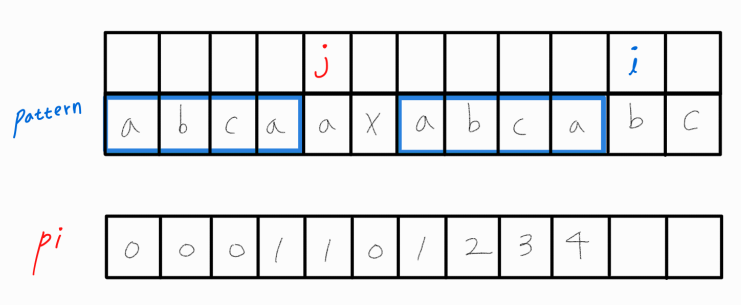
구해놨던 pi 배열의 i - 1번째 인덱스 요소 값은 4이다.
이는 i - 1번째까지의 부분 문자열의 LPS 길이는 4라는 의미이며, 해당 부분 문자열은 당연히 접두사와 접미사가 길이 4만큼 같은 상태이다.
또한, 해당 접두사와 접미사는 다음과 같이 해석해 볼 수 있다.
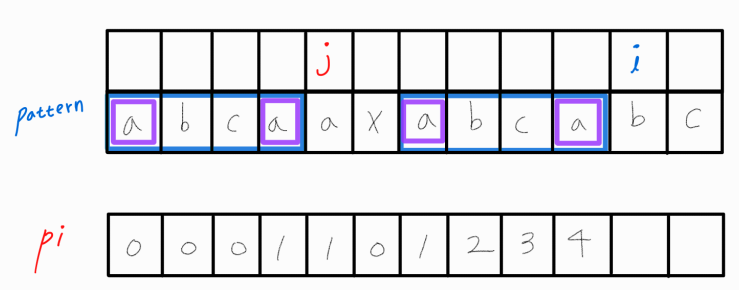
각 접두사/접미사 또한 각각 LPS 길이가 1인 상태이다.
이는 i - 1번째 까지의 부분 문자열에서 LPS의 길이는 4이지만, 길이가 4인 경우를 제외한다면 그 다음으로 긴 길이는 1이라는 의미이다.
우리는 이 경우에서 접두사/접미사에 문자 하나를 더 이어붙여볼 수 있는지 확인하면 된다.
그렇다면 j는 1번째 인덱스로 가면 된다. 왜?? 2번째로 긴 LPS 길이가 1임을 알아냈으니까.
2번째로 긴 LPS 길이는 pi[j - 1]을 통해 접근할 수 있다. 왜?? j - 1번째 인덱스까지의 접두사 안에서 접두사 == 접미사 길이정보가 pi[j - 1]에 담겨있으니까!
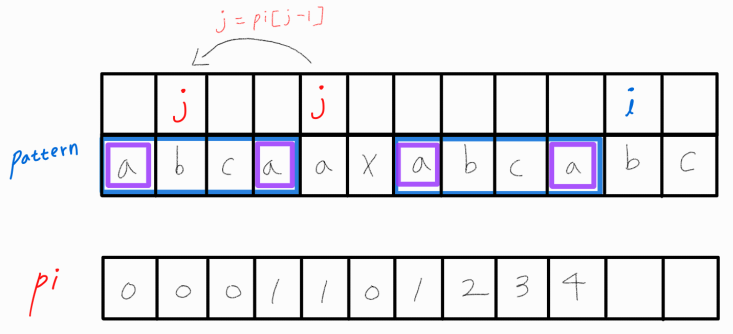
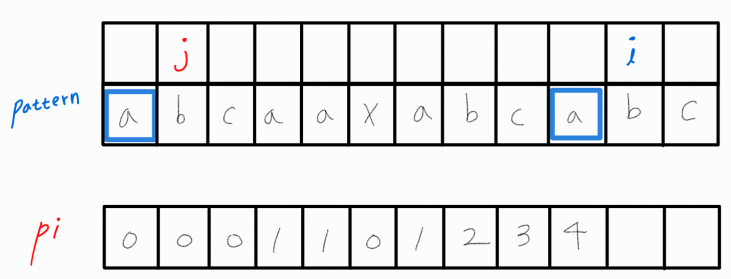
j를 옮긴 후, i와 비교해보니 i와 j가 같다.
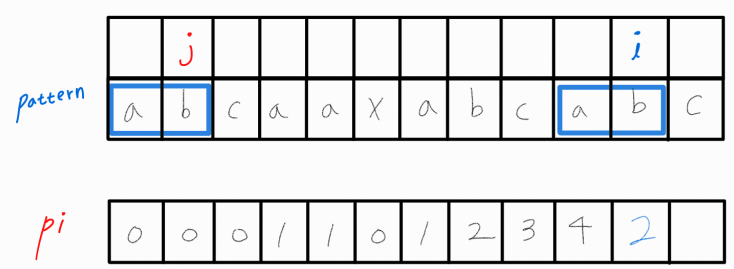
그러므로 pi[ i ]에 j + 1을 삽입해주고 i와 j 모두 1씩 증가시켜준다.
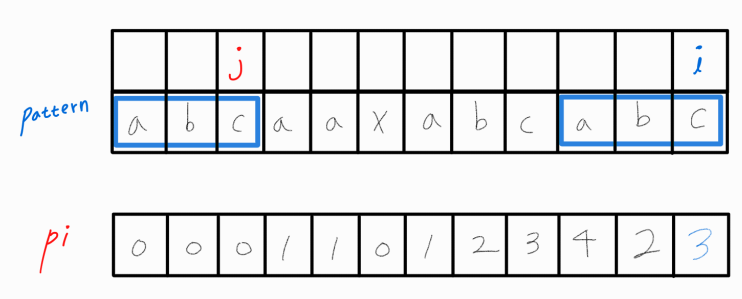
나머지 로직도 기존과 같이 진행해주면 위와 같은 pi 배열이 완성된다.
그래서 KMP 알고리즘이 뭔데?
우리는 KMP 알고리즘을 이해하기 위한 2가지 사전지식을 모두 습득했다.
KMP 알고리즘의 메인 로직은 LPS 알고리즘에서 사용한 방식과 매우 흡사하다. 이유는 접두사와 접미사가 같을 때, 해당 길이만큼 점프해주는 것이 핵심이기 때문이다.
KMP 알고리즘의 로직을 이해하기 전, 전체 코드를 먼저 보여주겠다.
Python 코드 ( KMP 알고리즘 )
# KMP algorithm
# create pi array by LPS
def create_pi(pattern):
pattern_length = len(pattern)
pi = [0 for _ in range(pattern_length)]
j = 0
for i in range(1, pattern_length):
while j > 0 and pattern[i] != pattern[j]:
j = pi[j - 1]
if pattern[i] == pattern[j]:
j += 1
pi[i] = j
return pi
# main logic
def kmp(word, pattern):
pi = create_pi(pattern)
word_length = len(word)
pattern_length = len(pattern)
# 패턴이 매칭된 횟수
matched_cnt = 0
# 패턴이 매칭되기 시작한 포인트(인덱스)
matched_point = []
p_idx = 0
for w_idx in range(word_length):
while p_idx > 0 and word[w_idx] != pattern[p_idx]:
p_idx = pi[p_idx - 1]
if word[w_idx] == pattern[p_idx]:
if p_idx == pattern_length - 1:
matched_cnt += 1
matched_point.append(w_idx - pattern_length + 1)
p_idx = pi[p_idx]
else:
p_idx += 1
print(matched_cnt)
print(matched_point)
if __name__ == "__main__":
word = "ababdababcabbababcababcababa"
pattern = 'ababcaba'
kmp(word, pattern)
LPS 알고리즘으로 pi 배열을 만들어주고 pi 배열을 활용해 시간복잡도 O(N)으로 매칭되는 패턴이 어디에, 몇 개 존재하는지 알아내는 로직이다.
예시를 그림으로 들어보며 이해해보자.
문자열(word) : ababdababcabbababcababcababa
패턴(pattern) : ababcaba
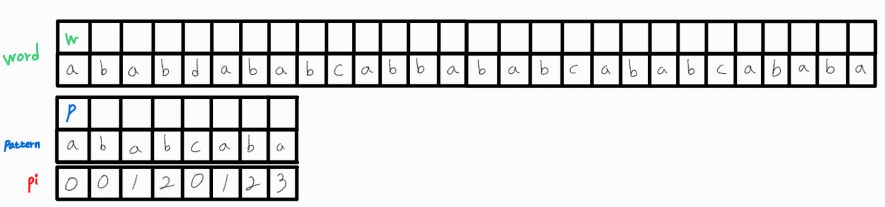
w는 현재 비교하고 있는 word의 인덱스 번호 w_idx이고, p는 현재 비교하고 있는 pattern의 인덱스 번호 p_idx이다.
pi 배열은 LPS 알고리즘을 통해 도출한 pi 배열이다.
현재 w_idx와 p_idx는 같으므로 w_idx와 p_idx 모두 1씩 증가시켜 다음 문자도 매칭되는지 확인해준다.
(중략 ... )
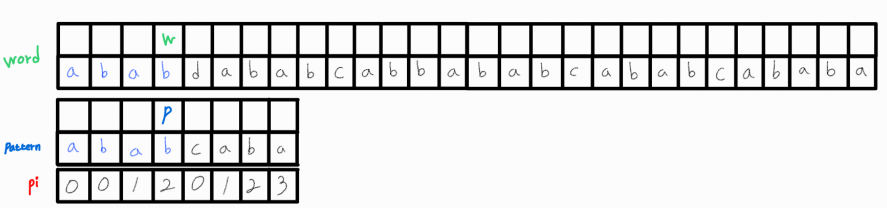
현재까지 패턴이 매칭되는 상태이다. 두 인덱스 번호를 모두 1씩 증가시켜 다음 인덱스 요소들도 서로 비교해보자.
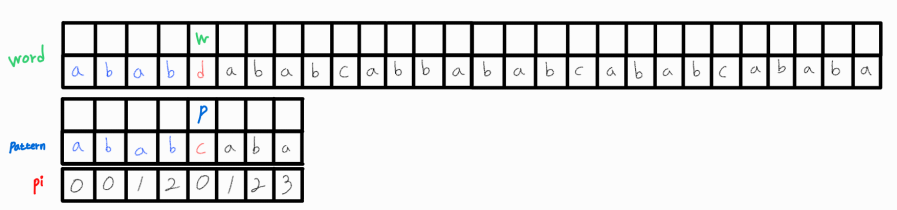
아쉽게도 매칭되지 않는다. word의 0번째 인덱스로 시작하는 부분 문자열은 패턴과 매칭되지 않았다는 의미.
브루트포스 방식이었다면 0번째 인덱스 다음인 1번째 인덱스로 시작하는 부분 문자열을 패턴과 비교해 보았겠지만, 여기서 pi 배열을 활용해 불필요한 연산을 생략한다. 이 로직이 KMP 알고리즘의 핵심이다.
Python 코드에서 이 부분은 다음과 같이 구현하였다.
for w_idx in range(word_length):
# 패턴이 일부 매칭되고 있었는데 그 다음 문자는 매칭되지 않았을 때 p_idx 값을 pi배열을 참조해 변경
while p_idx > 0 and word[w_idx] != pattern[p_idx]:
p_idx = pi[p_idx - 1]
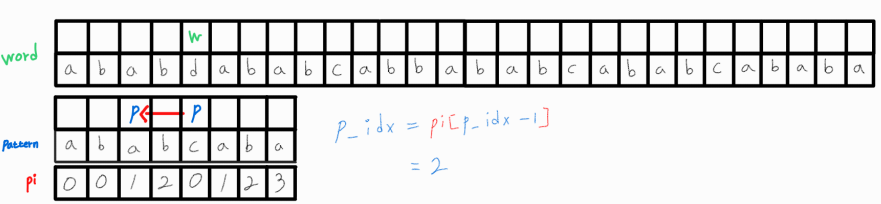
LPS 알고리즘을 활용해 pi 배열을 구할 때와 같은 개념으로, pattern에서 p_idx - 1 번째까지의 부분 문자열에서의 LPS 길이를 활용할 수 있다.
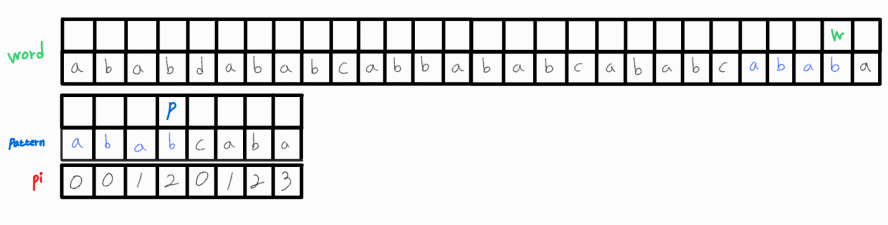
w_idx가 0 ~ 3 까지와 p_idx가 0 ~ 3 까지는 같았으나 4번째 인덱스에서 같지 않았으므로, pi[3] = 2 인 정보를 활용하면 pattern[0 ~ 1] 와 word[2 ~ 3]은 이미 같다는 정보를 함께 내포하고 있는 것이다.
그러므로 w_idx를 롤백시키지 않고 그대로 둔 채로, 그리고 p_idx를 0으로 초기화시키지 않은 채로 pattern[2]와 word[4]를 비교해도 무방한 것이다.
이해가 어려울 수 있는데, 이를 그림으로 표현하면 아래와 같다.
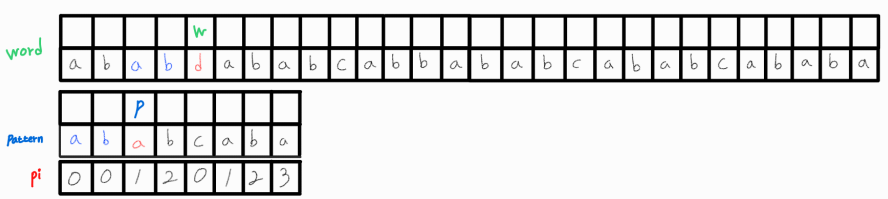
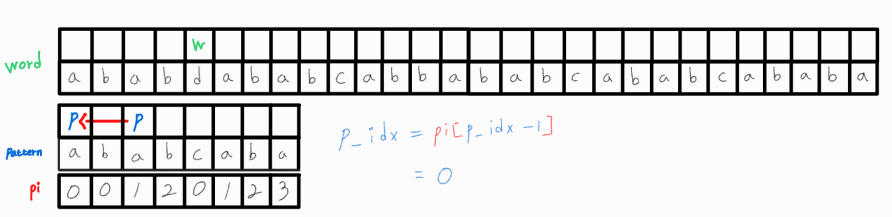
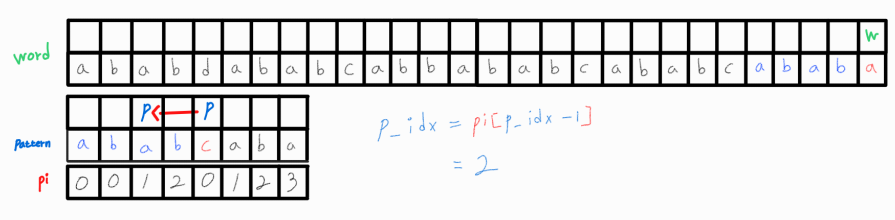
하지만 이 두 문자 또한 같지 않으므로 p_idx = pi[p_idx - 1] = 0으로 변경해준다.
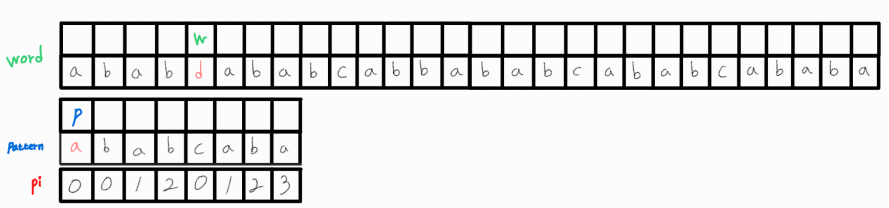
변경된 p_idx의 문자와 w_idx 문자를 비교해도 같지 않다.
p_idx는 이미 0이므로 w_idx를 1 증가시켜 다시 매칭되는지 확인한다.
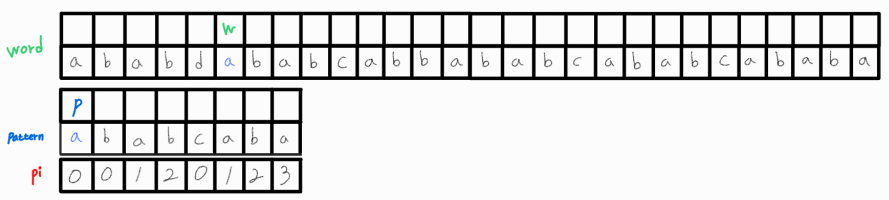
(중략 ... )
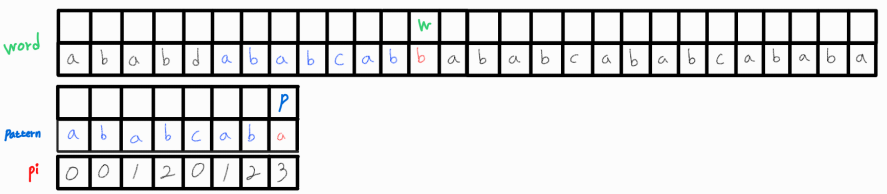
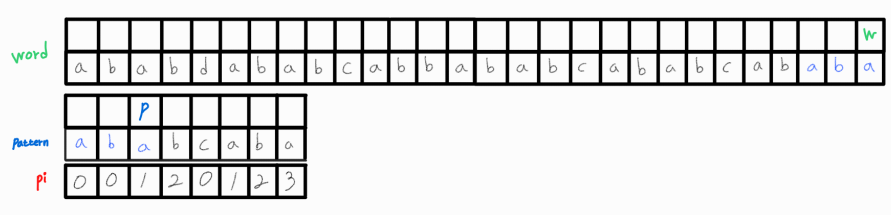
아쉽게도 pattern의 마지막 인덱스에서 불일치가 일어났다.
p_idx 값을 pi[p_idx - 1]로 변경시켜주고 재비교를 해보자.
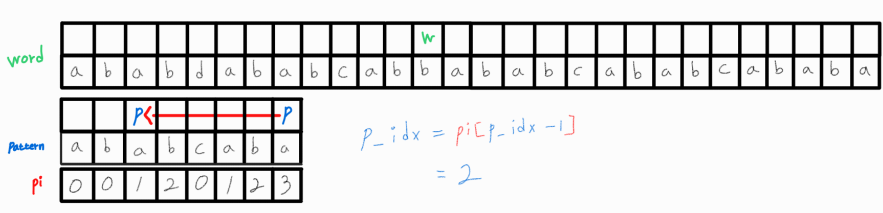
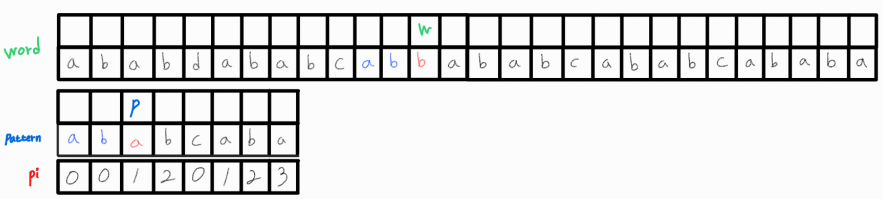
재비교 후에도 일치하지 않으므로 p_idx를 다시 변경해준다.
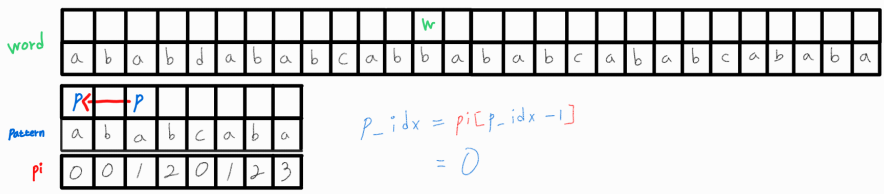
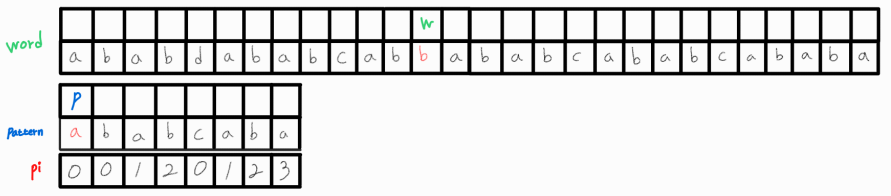
이 또한 일치하지 않는다. w_idx를 1 증가시켜준다.
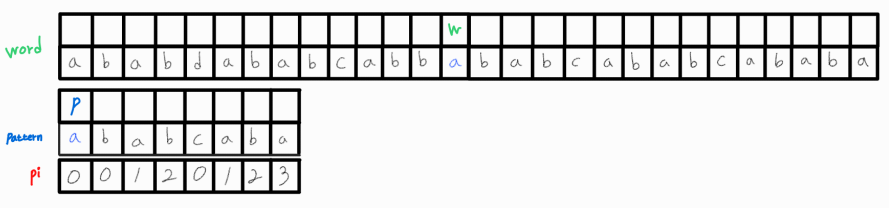
매칭되었으니, w_idx와 p_idx를 1씩 함께 증가시키며 계속 비교해준다.
(중략...)
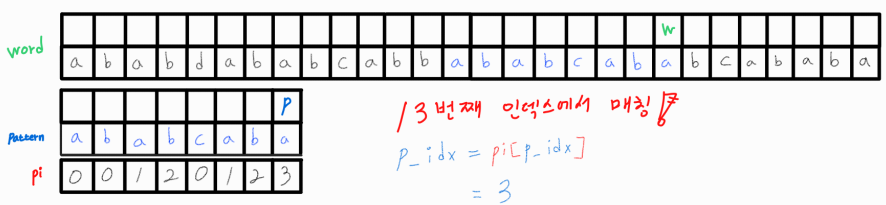
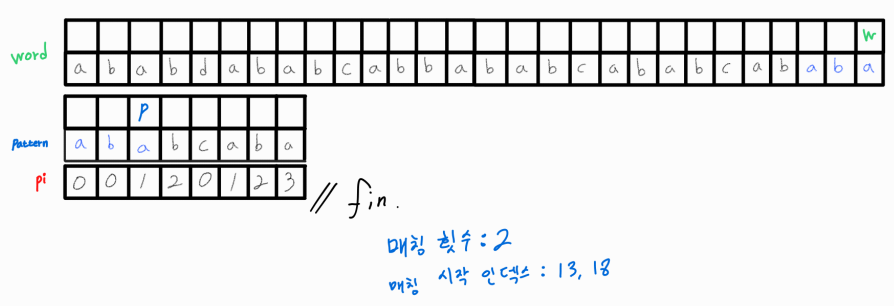
드디어 패턴이 매칭되는 위치를 찾았다!
매칭된 이후 추가로 매칭되는 위치를 찾고 싶다면 p_idx의 위치를 pi[p_idx]로 변경시켜주어야 한다. 왜냐하면 매칭된 부분과 겹치는 또 다른 매칭되는 위치가 존재할 수 있기 때문! 여기서도 pi 배열을 활용해 LPS 길이만큼은 같다는 점을 이용해 중복 연산을 방지해준다.
Python 코드에서 이 부분은 다음과 같이 구현하였다.
if word[w_idx] == pattern[p_idx]:
if p_idx == pattern_length - 1:
matched_cnt += 1
matched_point.append(w_idx - pattern_length + 1)
# 패턴이 매칭되었을 때 p_idx 값 조정
p_idx = pi[p_idx]
else:
p_idx += 1
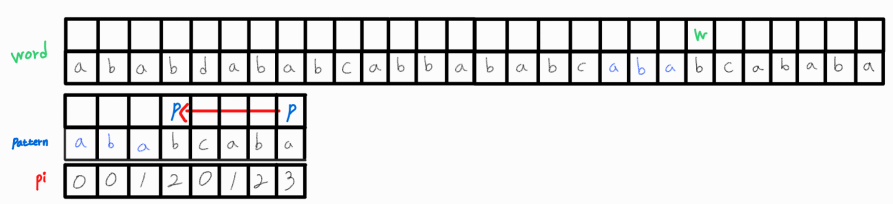
또한 w_idx를 1 증가시켜 다음 문자도 패턴과 매칭되고 있는지 확인해준다.
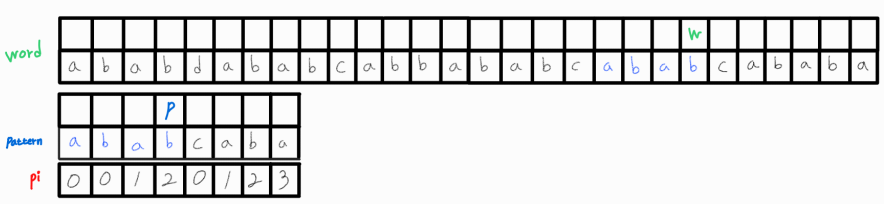
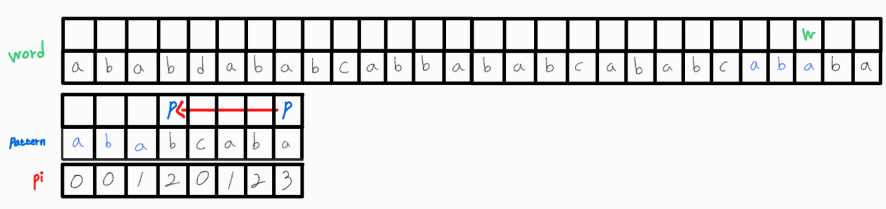
(중략 ...)

한 번 더 매칭되는 부분을 찾아냈다!
매칭되었으므로 p_idx 값을 pi[p_idx]로 변경시켜주고 아까와 같이 로직을 수행해준다.
(이후 설명은 표 그림만 첨부하고 생략하겠음 ... )
응용 문제
KMP 알고리즘을 그대로 적용하면 풀 수 있는 백준 문제가 하나 있다.
링크 : [백준 1786번 - 찾기]
위 문제는 문자열과 패턴의 최대 길이가 100만이므로, KMP 알고리즘을 사용하지 않으면 무조건 시간초과를 겪게 된다.
KMP 알고리즘을 구현한 코드에서 크게 수정하지 않고도 풀 수 있으니 알고리즘 공부를 마쳤다면 한 번 풀어보는 것을 추천한다!
후기
KMP 알고리즘의 존재를 안 것은 1년 전 골드3 문제인 Cubeditor를 풀면서였다.
(링크 : 백준 1701번 - Cubeditor)
새로운 알고리즘을 사용해야 한다는 점에서 좌절감도 느꼈지만, 한 편으로 처음 들어보는 알고리즘이라 며칠 동안 이해하려고 애썼던 기억이 있다. (그 때 처음 교수님께 공부를 주제로 메일도 보내봤었다 ㅎ.ㅎ)
최근 KMP 알고리즘을 활용해야 하는 백준 1786번 - 찾기 문제를 접하면서 다시 KMP 알고리즘을 공부하게 되었고, 다시 공부하게 된 겸 1주일이라는 시간을 들여 블로그 포스팅으로 연결지을 수 있었다.
글이 난잡하고 길어 가독성이 떨어질 수 있지만, 내가 다른 사람들의 글을 보며 지식을 습득하듯 다른 누군가도 도움을 받게 되면 좋겠다..!!
'알고리즘' 카테고리의 다른 글
| [알고리즘] 위상 정렬(Topological Sort) [ 백준 2252번 - 줄 세우기 ] (0) | 2024.11.26 |
|---|---|
| [알고리즘] 다익스트라(Dijkstra) [ 백준 1916번 - 최소비용 구하기 ] (0) | 2024.05.22 |
| [알고리즘] 0-1 Knapsack Problem (0-1 냅색 문제)[SWEA 3282번 - 0/1 Knapsack] (2) | 2024.05.16 |
| [알고리즘] LIS(최장 증가 부분 수열), 응용 문제 3가지 (0) | 2024.04.16 |
| [알고리즘] 플로이드-워셜(Floyd-Warshall) 알고리즘 [백준 11404번 - 플로이드] (2) | 2023.10.27 |



