
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 너비 우선 탐색
- 데이터베이스
- 구현
- 문자열
- 다익스트라
- 다이나믹 프로그래밍
- DFS
- 백준알고리즘
- 프로그래머스
- javascript
- SWEA
- BFS
- 파이썬
- 이분 탐색
- 브루트포스 알고리즘
- 브루트포스
- 그래프 이론
- 오라클
- SW Expert Academy
- DP
- 백준 알고리즘
- C++
- 그리디 알고리즘
- Python
- 너비우선탐색
- 자바스크립트
- oracle
- 그래프 탐색
- 스택
- 백트래킹
- Today
- Total
민규의 흔적
[알고리즘] 다익스트라(Dijkstra) [ 백준 1916번 - 최소비용 구하기 ] 본문
2024년 5월 22일
다익스트라( 데이크스트라, Dijkstra )
다익스트라 알고리즘은 그래프의 한 정점에서 모든 정점까지의 최단 경로를 각각 구하는 알고리즘으로, 에츠허르 다익스트라가 고안한 알고리즘이다.
다이나믹 프로그래밍을 활용해 중복 연산을 방지하며 최단 경로를 구한다는 특징을 지니고 있다.
플로이드-워셜 알고리즘과는 다르게, 다익스트라 알고리즘은 그래프 내에 음의 가중치를 가진 간선이 존재한다면 사용할 수 없다.
추가로 둘의 차이점이라면 다익스트라 알고리즘은 하나의 노드로부터 최단 경로(one - to - all)를 구하는 알고리즘인 반면,
플로이드-워셜 알고리즘은 가능한 모든 노드쌍들에 대한 최단 경로(all - to - all)를 구하는 알고리즘이라는 점이다.
(플로이드-워셜 알고리즘에 대한 포스팅 : https://ymg5218.tistory.com/60 )
다익스트라 알고리즘은 실제 컴퓨터 네트워크에서 각 엔드포인트끼리, 혹은 라우터 끼리의 최단 경로를 계산하거나 GPS에서 출발지와 목적지 사이의 최단 경로를 계산할 때 사용되는 등 일상 생활에 드넓게 녹아있는 알고리즘이다.
접근 방법
사전 준비

위와 같은 단방향 그래프가 존재한다고 가정하겠다.
우리는 1번 노드를 기준으로 나머지 모든 노드로 도달하는데에 필요한 최소 비용(최단 경로)을 구할 것이다.
우선, 1번 노드로부터 나머지 노드들에 대한 거리 정보를 담아둘 것이다.
1번 노드는 시작점이므로 거리를 0으로 설정해둔 뒤, 나머지 노드들까지의 거리를 아직 모르기에 무한히 큰 수를 뜻하는 INF로 초기화 시켜준다.
1번 노드에서 뻗어나가는 간선을 하나씩 살펴보자.
우선 2번 노드로 갈 수 있는 간선이 존재한다.
해당 간선의 거리는 2이므로, 기존의 2번 노드까지의 거리인 INF와 2를 비교하여 더 작은 수인 2를 현재 2번 노드까지의 최단 거리로 갱신해준다.
1번 노드와 연결된 또 다른 간선을 살펴보자.
3번 노드로 갈 수 있는 간선이 존재하기에, 해당 간산의 거리인 3과 기존의 3번 노드까지의 거리인 INF를 비교하여 더 작은 수인 3을 현재 3번 노드까지의 최단 거리로 갱신해준다.
1번 노드를 시작 노드로 하는 간선은 더 이상 존재하지 않기에, 이제 1번 노드에서 바로 갈 수 있는 2번 노드와 3번 노드에서 뻗어나가는 간선을 확인해 볼 것이다.
2번 노드를 먼저 확인해보자.
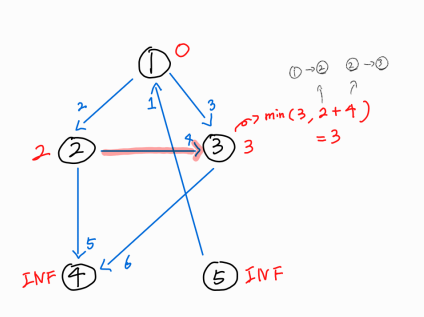
2번 노드에서 뻗어나가는 간선들 중, 3번 노드로 뻗어나가는 간선이 존재한다.
이는 1 -> 3 으로 가는 새로운 경로로, 1 -> 2 + 2 -> 3 = 6 거리의 경로이다.
새로운 경로를 찾았으나, 기존의 1 -> 3 경로의 최단 거리인 3보다 크므로 갱신시켜 주지는 못한다.
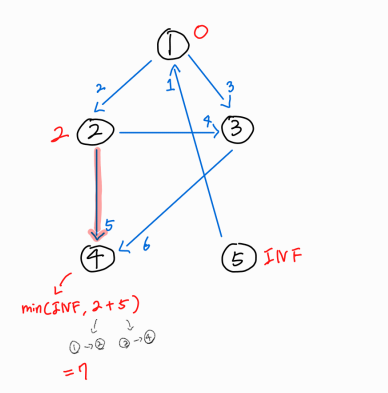
2번 노드에서 뻗어나가는 간선들 중, 4번 노드로 뻗어나가는 간선 또한 존재한다.
이는 기존에 없던 1 -> 4로 갈 수 있는 경로로, 1 -> 2 + 2 -> 4 = 2 + 5 = 7 거리의 경로이다.
새로운 경로가 기존의 INF보다 작으므로, 1 -> 4 경로의 최단 거리는 7로 갱신시켜준다.
더 이상 2번 노드에서 뻗어나가는 간선이 없기 때문에, 2번 노드에서 바로 갈 수 있는 3번 노드와 4번 노드에서 뻗어나가는 간선을 확인해보자.
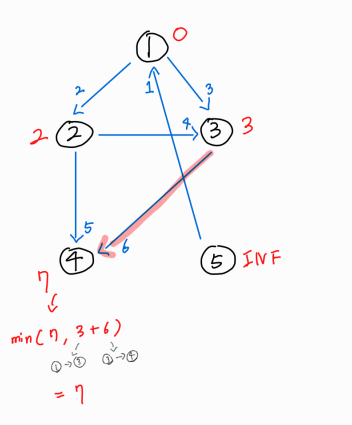
3번 노드에서 뻗어나가는 간선을 보니, 3 -> 4 간선이 존재한다.
이는 1번 노드에서 4번 노드로 가는 새로운 경로인 1 -> 3 -> 4 이므로 1 -> 3 + 3 -> 4 = 3 + 6 = 9 거리의 경로이다.
이는 기존 경로의 거리보다 길기 때문에 갱신시켜 주지는 못한다.
1번 노드에서 뻗어나가 도달할 수 있는 노드는 모두 도달했으며, 그 경로의 유효한 간선까지 모두 확인했다.
5 -> 1 간선이 남아있으나, 이는 1번 노드에서 출발해서는 결코 거칠 수 없는 독립된 간선이기에 고려하지 않고 고려할 필요도 없다.
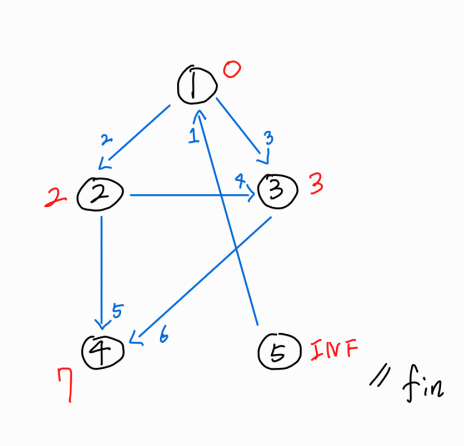
로직이 끝난 후, 1번 노드에서 각 노드까지의 최단 거리는 다음과 같다.
1 -> 2 : 2
1 -> 3 : 3
1 -> 4 : 7
1 -> 5 : INF(경로 없음)
시간 복잡도
V : 노드의 개수, E = 간선의 개수일 때,
다익스트라 알고리즘의 기본 시간 복잡도는 O(V^2 + E) 이다.
각 반복문마다 미방문 노드 중 출발점으로부터 현재까지 계산된 최단 거리를 가지는 노드를 찾는데 O(V^2)의 시간이 필요하다. 이는 모든 노드( O(V) )에 대해 원소 V개 들어간 배열에서 선형 탐색을 하며 최소값을 추출( O(V) )하기 때문이다.
또한 각 노드마다 이웃한 노드의 최단 거리를 갱신하기 위해 모든 간선들( O(E) )을 확인하는 작업이 필요하기 때문에 최종적인 시간 복잡도는 O(V^2 + E) 이다.
이는 우선순위 큐 자료구조를 사용해 시간 복잡도를 O(E lg V)까지 줄일 수 있다.
각 노드마다 인접한 간선을 모두 검사하는 작업과 우선순위 큐에 간선을 넣고 빼는 작업을 수행하는데,
각 노드는 1번씩만 방문되므로 모든 간선을 검사하면 O(E)의 시간이 걸린다.
최소 힙 구조의 우선순위 큐에 각 노드와 연결된 모든 간선들을 넣고 빼는 과정은 O(lg E)가 걸리기 때문에 모든 간선을 우선순위 큐에 넣고 뺀다 했을 때의 총 시간 복잡도는 O(E lg E)이다.
만약, 그래프에서 중복 간선을 포함하지 않는다면 E는 항상 V^2 이하이다.
따라서 lg E < lg(V^2), lg(V^2) = 2 lg V 이므로 O(lg V)로 표현할 수 있다.
따라서 우선순위 큐 자료구조를 사용한 시간 복잡도는 O(E lg V)이다.
응용 문제
실제 다익스트라를 활용한 문제를 풀어보자. 백준 1916번 - 최소비용 구하기 문제를 추천한다.
문제 풀이
문제 링크 : 백준 1916번 - 최소비용 구하기
문제
N개의 도시가 있다. 그리고 한 도시에서 출발하여 다른 도시에 도착하는 M개의 버스가 있다. 우리는 A번째 도시에서 B번째 도시까지 가는데 드는 버스 비용을 최소화 시키려고 한다. A번째 도시에서 B번째 도시까지 가는데 드는 최소비용을 출력하여라. 도시의 번호는 1부터 N까지이다.
입력
첫째 줄에 도시의 개수 N(1 ≤ N ≤ 1,000)이 주어지고 둘째 줄에는 버스의 개수 M(1 ≤ M ≤ 100,000)이 주어진다. 그리고 셋째 줄부터 M+2줄까지 다음과 같은 버스의 정보가 주어진다. 먼저 처음에는 그 버스의 출발 도시의 번호가 주어진다. 그리고 그 다음에는 도착지의 도시 번호가 주어지고 또 그 버스 비용이 주어진다. 버스 비용은 0보다 크거나 같고, 100,000보다 작은 정수이다.
그리고 M+3째 줄에는 우리가 구하고자 하는 구간 출발점의 도시번호와 도착점의 도시번호가 주어진다. 출발점에서 도착점을 갈 수 있는 경우만 입력으로 주어진다.
출력
첫째 줄에 출발 도시에서 도착 도시까지 가는데 드는 최소 비용을 출력한다.
알고리즘 분류
- 그래프 이론
- 다익스트라(데이크스트라)
- 최단 경로
문제 접근
한 노드에서 특정 다른 노드까지의 최단 거리를 구하는 문제이다.
중간에 어떤 노드를 거치게 될지 모르니, 결국 출발 노드에서 나머지 노드들에 대한 모든 최단 거리를 계산해 로직이 종료되면 도착 노드까지의 최단 거리를 출력하면 되는 문제로 보인다.
이 문제는 함정이 있다.
1. 노드의 개수는 최대 10**3개 이다.
2. 간선의 개수는 최대 10**5개 이다.
3. 우선순위 큐를 사용한다면 최악의 경우 10**5 * lg (10**3) 만큼 연산을 수행할 것이다.
4. 하지만 시간 제한이 0.5초이다. 간선을 모두 확인하면 시간 초과를 피할 수 없다.
이에 적절히 가지치기 해주는 작업을 해주어야 한다.
어디에 가지치기를 하는가? 볼 필요 없는 경로에 대해 가지치기를 하면 된다.
이는 아래 입력 예제를 통해 자세히 살펴보자.
입력 예제
5
8
1 2 2
1 3 3
1 4 1
1 5 10
2 4 2
3 4 1
3 5 1
4 5 3
1 5
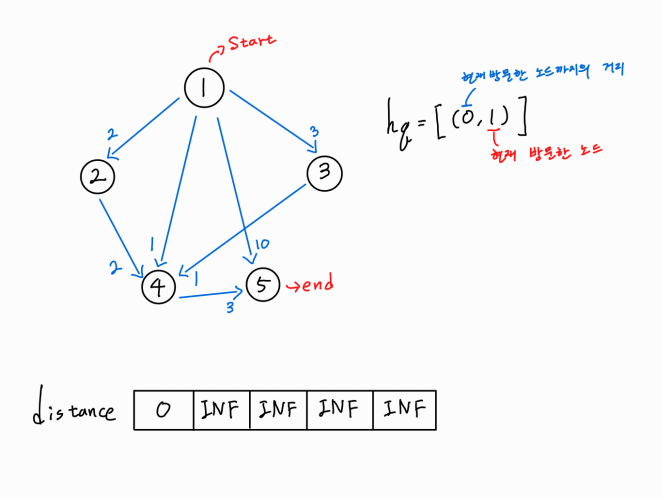
출발점은 1번 노드이며, 도착점은 5번 노드이다.
각 노드 간의 간선을 위와 같이 주어졌으며,
distance 배열은 출발점인 1번 노드에서 나머지 노드들까지의 최단 거리를 담는 배열이다.
1번째 인덱스는 출발점에서 출발점까지의 거리를 의미하므로 0을 삽입하고,
나머지 인덱스에 대해서는 아직 거리를 모르기에 INF로 초기화하여 준다.
우선순위 큐 hq를 선언해주었으며, 현재 방문한 노드까지의 거리를 기준으로 최소 힙 정렬을 할 것이다.
이는 이후 가지치기를 수월하게 하기 위함이다.
이 로직은 hq가 빌 때까지 수행된다.
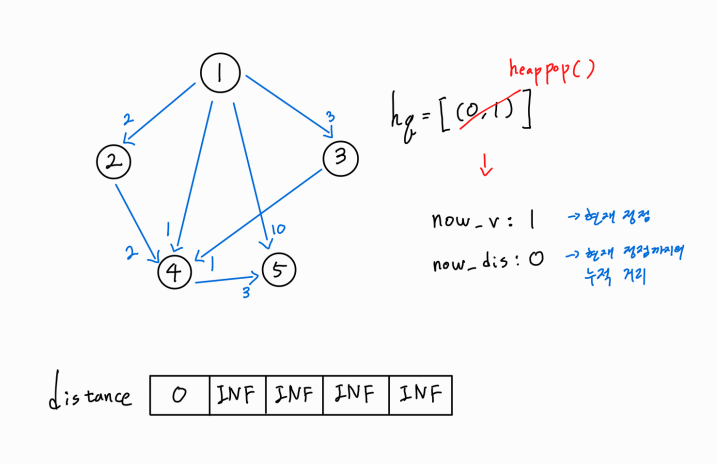
hq를 heappop()하여 추출한 값을 now_v, now_dis에 담아낸다.
각각 현재 방문한 정점과, 현재 방문한 정점까지의 누적 거리를 의미한다.
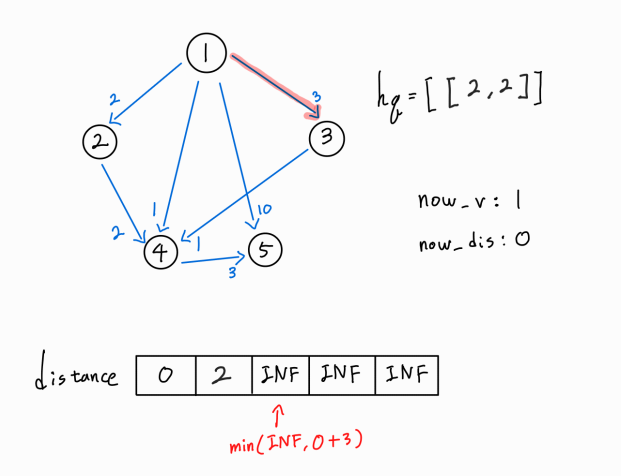
현재 방문 정점인 1번 정점에서 뻗어나가는 간선을 하나씩 확인해보자.
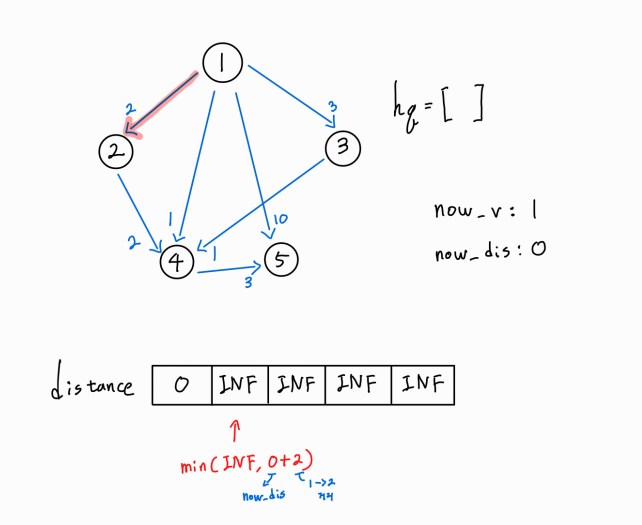
1 -> 2 간선이 존재한다.
2번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 1) 거리 + ( 1 -> 2 ) 거리 를 기존의 2번 노드까지의 최단 거리와 비교한다.
새로운 경로가 더 거리가 짧은 최단 거리이므로 distance[2] 값을 갱신시켜주고, 해당 노드까지의 누적 거리와 해당 노드 정보를 hq에 push해 준다.
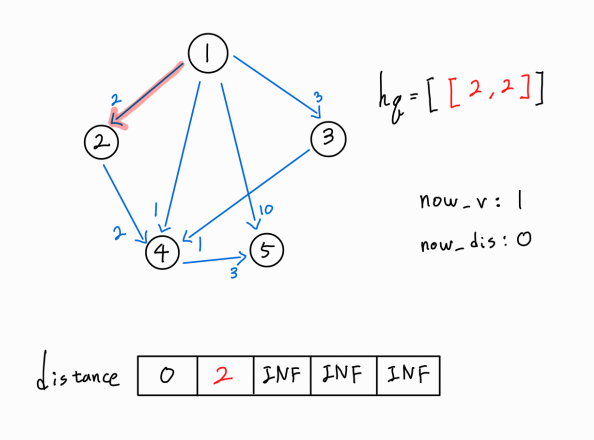
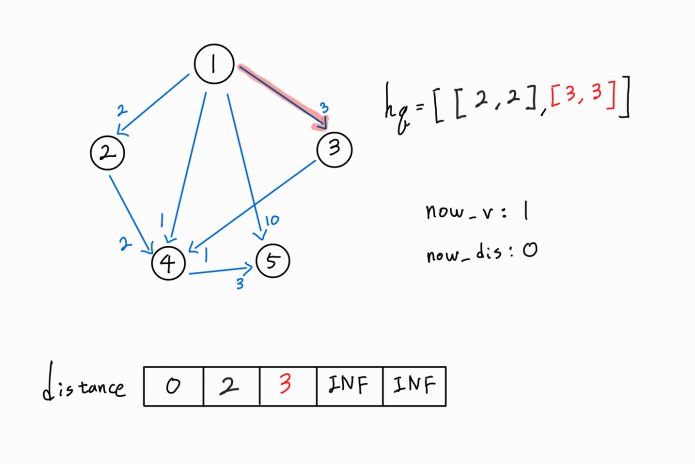
현재 노드인 1번 노드에서 뻗어나가는 또 다른 간선을 확인해보자.
1 -> 3 간선이 존재한다.
3번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 1) 거리 + ( 1 -> 3 ) 거리 를 기존의 3번 노드까지의 최단 거리와 비교한다.
새로운 경로가 더 거리가 짧은 최단 거리이므로 distance[3] 값을 갱신시켜주고, 해당 노드까지의 누적 거리와 해당 노드 정보를 hq에 push해 준다.
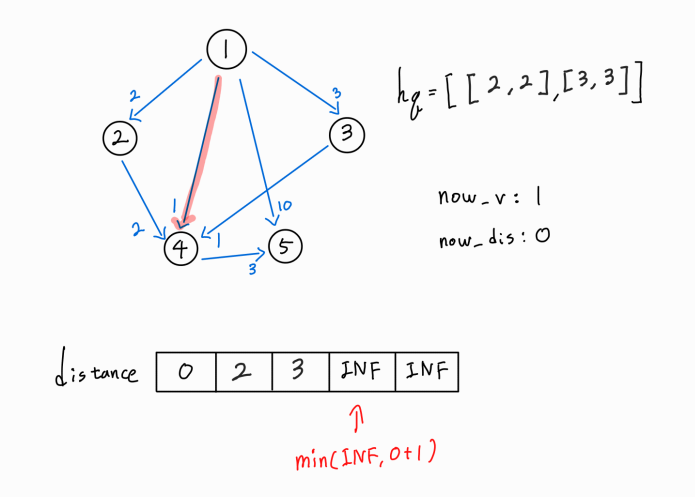
현재 방문 노드에서 뻗어나가는 또 다른 간선을 확인해보니, 1 -> 4 간선이 존재한다.
4번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 1) 거리 + ( 1 -> 4 ) 거리를 기존의 4번 노드까지의 최단 거리와 비교한다.
새로운 경로가 더 거리가 짧은 최단 거리이므로 distance[4] 값을 갱신시켜주고, 해당 노드까지의 누적 거리와 해당 노드 정보를 hq에 push해 준다.
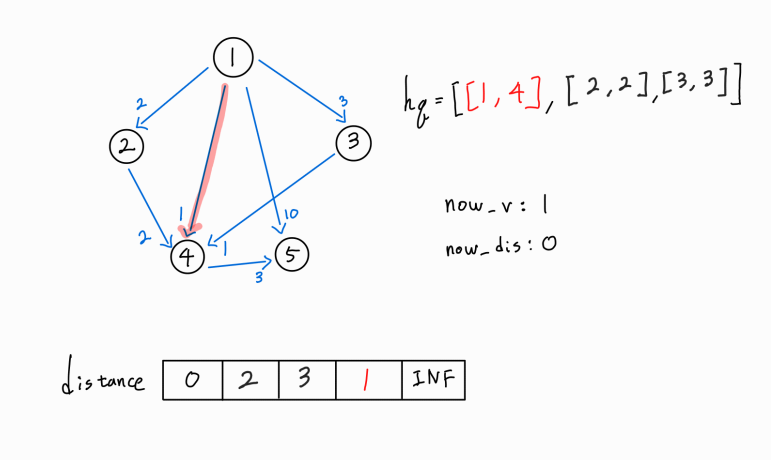
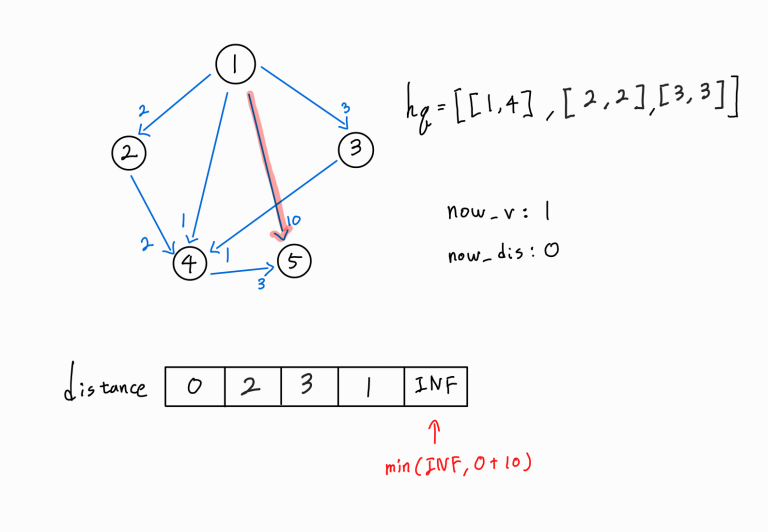
1 -> 5 간선이 존재한다.
5번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 1) 거리 + ( 1 -> 5 ) 거리를 기존의 5번 노드까지의 최단 거리와 비교한다.
새로운 경로가 더 거리가 짧은 최단 거리이므로 distance[5] 값을 갱신시켜주고, 해당 노드까지의 누적 거리와 해당 노드 정보를 hq에 push해 준다.
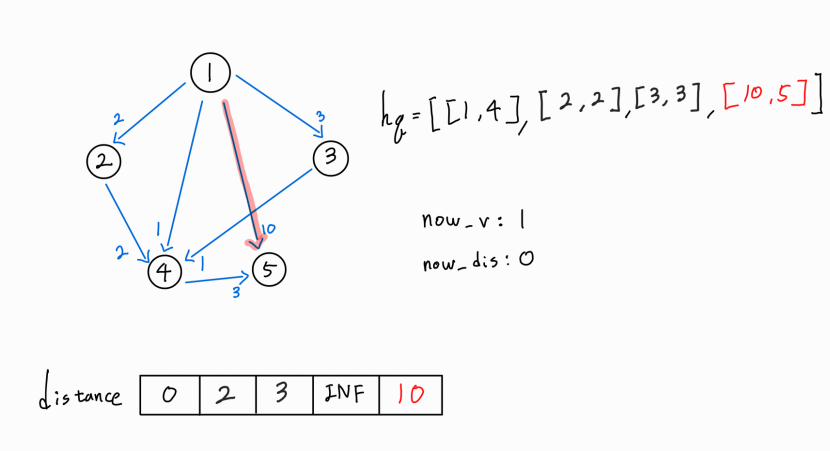
이제 현재 노드인 1번 노드에서 뻗어나가는 모든 간선을 확인해 보았으므로, 다시 hq를 heappop()하여 다음 경로를 확인해본다.
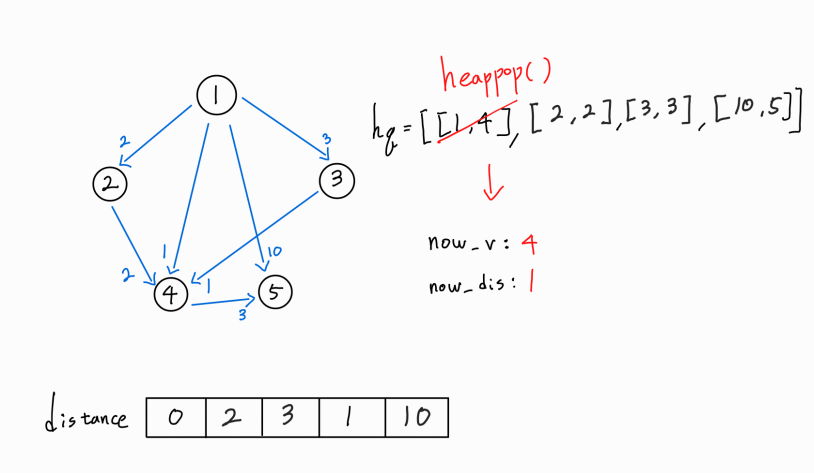
현재 방문 노드는 4번 노드이며, 1 -> 4 까지의 누적 거리는 1이다.
4번 노드에서 뻗어나가는 간선이 있는지 확인해보자.
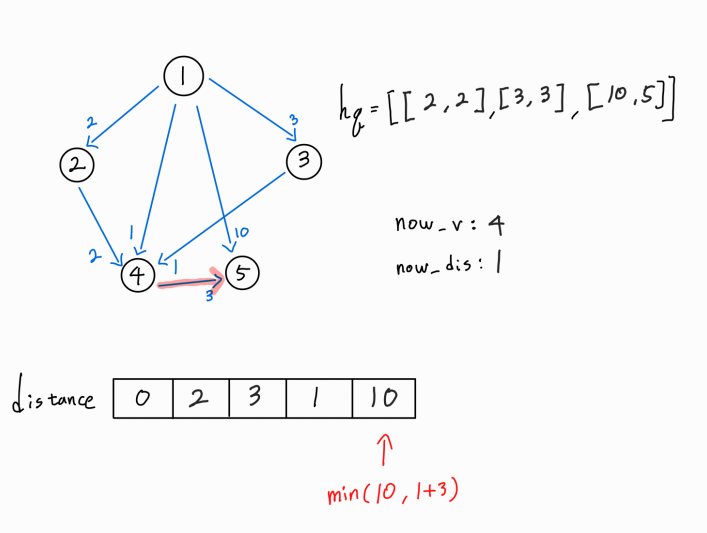
4 -> 5 간선이 존재한다.
5번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 4) 거리 + ( 4 -> 5 ) 거리를 기존의 5번 노드까지의 최단 거리와 비교한다.
새로운 경로가 더 거리가 짧은 최단 거리이므로 distance[5] 값을 갱신시켜주고, 해당 노드까지의 누적 거리와 해당 노드 정보를 hq에 push해 준다.
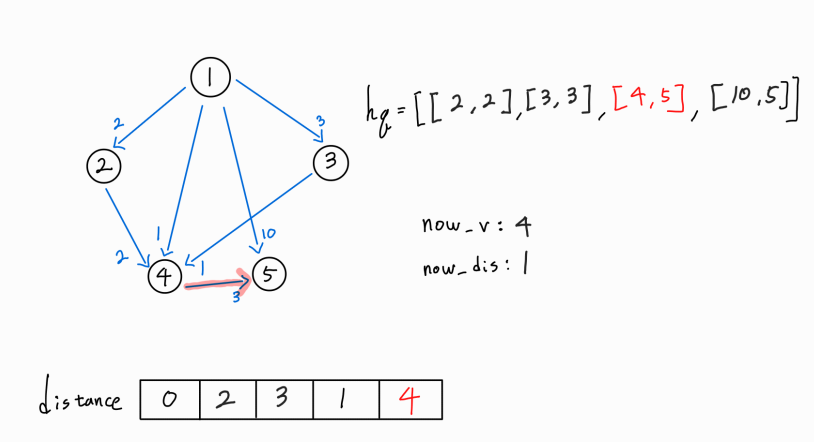
현재 노드인 4번 노드에서 뻗어나가는 간선이 더 이상 존재하지 않으므로 다음 경로를 확인해보자.
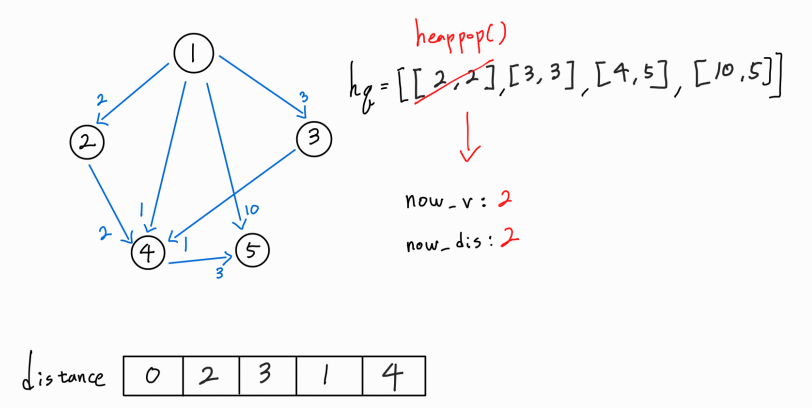
현재 방문 노드는 2번 노드이며, 1 -> 2 까지의 누적 거리는 2이다.
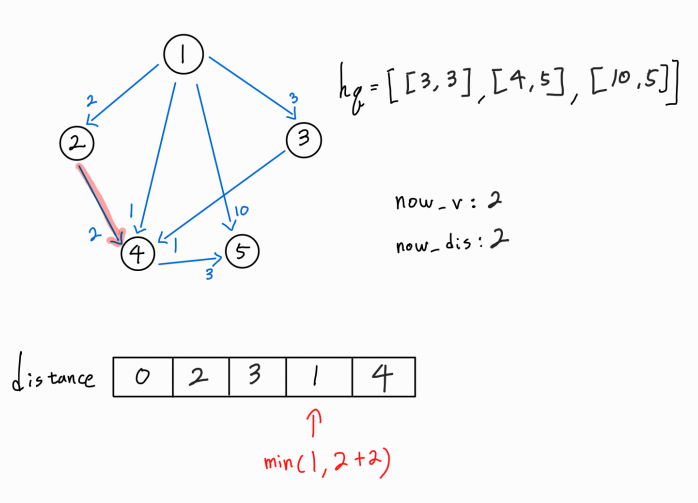
2번 노드에서 뻗어나가는 간선을 확인해보니 2 -> 4 간선이 존재함을 알아냈다.
4번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 2) 거리 + ( 2 -> 4 ) 거리를 기존의 4번 노드까지의 최단 거리와 비교한다.
새로운 경로가 기존 최단 거리보다 더 멀기 때문에 distance[4]를 갱신시켜주지 않고, hq에도 push하지 않는다.
더 이상 간선이 없기 때문에 다음 경로를 확인해보자.
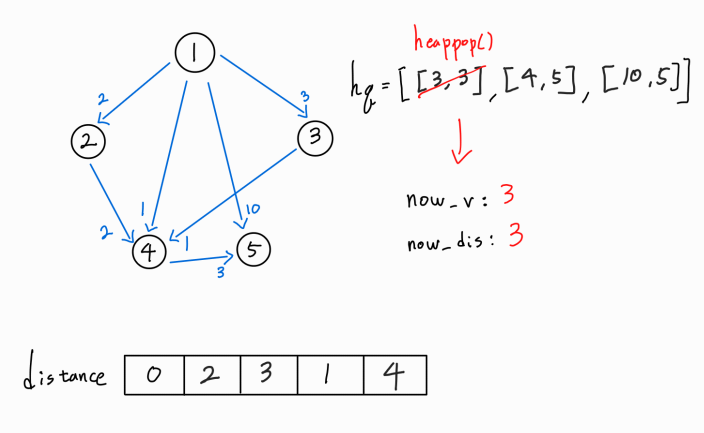
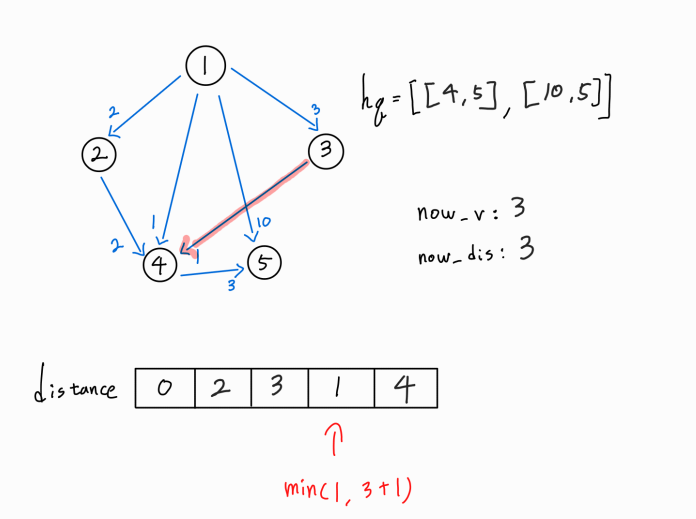
3 -> 4 간선이 존재한다.
4번 노드 까지의 새로운 경로가 확인되었으므로, (1 -> 3) 거리 + ( 3 -> 4 ) 거리를 기존의 4번 노드까지의 최단 거리와 비교한다.
새로운 경로가 기존 최단 거리보다 더 멀기 때문에 distance[4]를 갱신시켜주지 않고, hq에도 push하지 않는다.
더 이상 간선이 없기 때문에 다음 경로를 방문해보자.
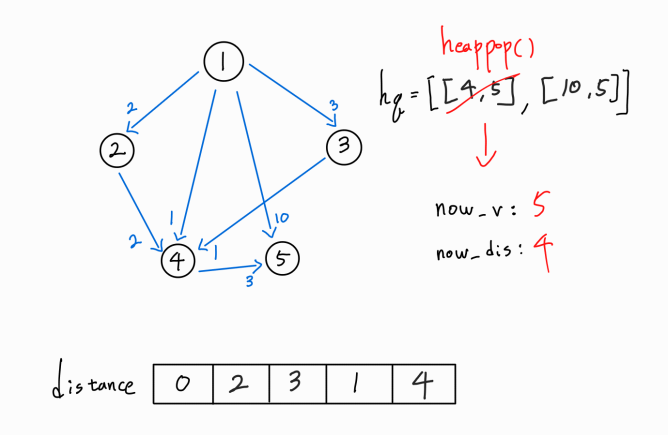
현재 방문 노드는 5번 노드이고, 1 -> 5 까지의 누적 거리는 4이다.
하지만 5번 노드에서 뻗어나가는 간선이 존재하지 않기에 로직 수행을 하지 않는다.
다음 경로를 확인해보자.
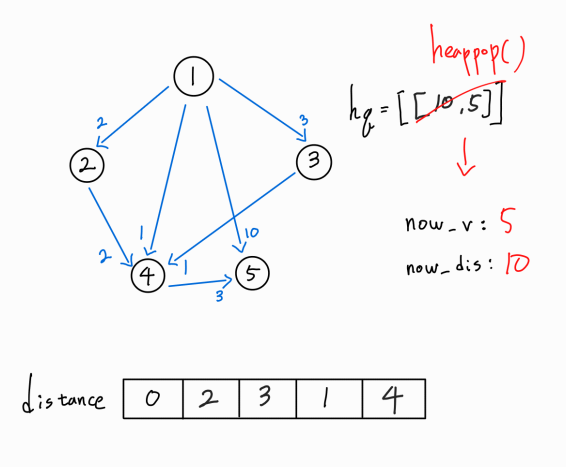
현재 방문 노드가 5, 1 -> 5 까지의 누적 거리가 10인 경로 정보를 받았다.
하지만, 1 -> 5 경로의 최단 거리는 이미 4이다.
따라서 해당 경로는 뒤에 어느 경로가 더 존재하여도 최단 경로일 수 없다.
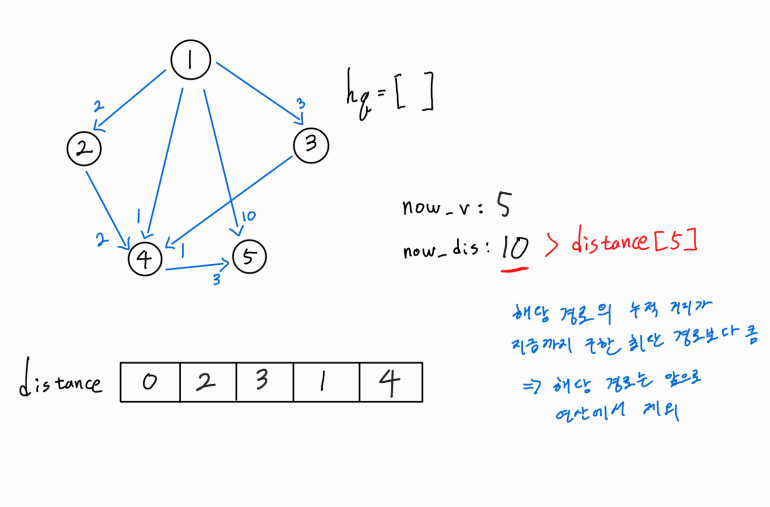
이런 경우는 뒤에 간선이 더 존재해도, 적어도 해당 경로로는 탐색을 진행하지 못하도록 가지치기 해주는 것이다.
해당 예시는 설명이 빈약하기에 뒤에서 추가로 설명하겠다.
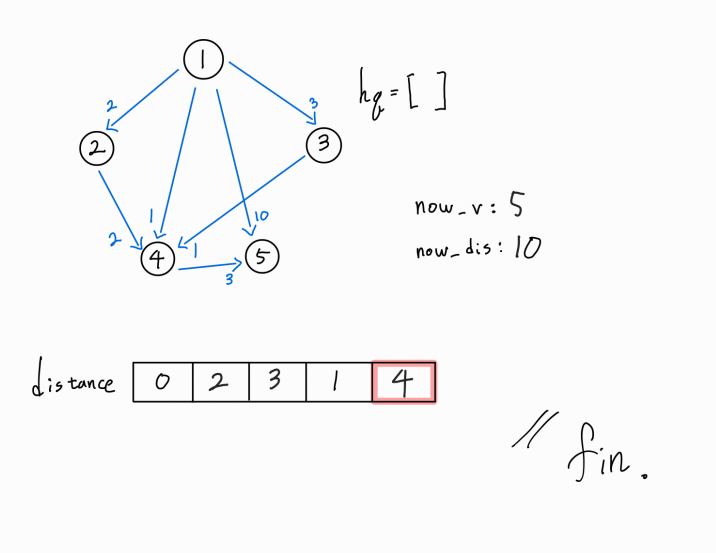
hq가 비었으므로 로직을 종료한다.
1번 노드에서 5번 노드까지의 최단 거리를 구하는 문제이므로, distance[5]인 4가 문제에서 원하는 정답이다.
가지치기
위에서 설명하였듯, 특정 노드까지의 경로가 여러 개 존재할 때 한 경로가 다른 경로보다 더 크다는 것이 밝혀졌다면 해당 경로를 포함하는 전체 경로는 결코 최단 경로일 수 없으므로 가지치기 해주어야 한다고 하였다.
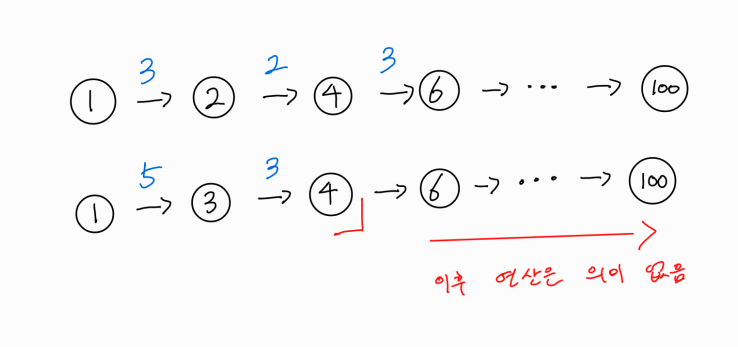
1번 노드에서 100번 노드까지 도달하는데 위와 같이 여러 경로가 존재할 수 있을 것이다.
1 -> 2 -> 4 -> 6 -> ... -> 100의 경우 2번 노드까지는 3, 4번 노드까지는 5, 6번 노드까지는 8 등등 각 노드까지의 최단 거리가 계산되어있는 상태이다.
여기서 1 -> 3 -> 4 -> 6 -> ... -> 100의 경우를 보자.
1 -> 4 까지 도달하는데 거리가 5 + 3으로 8이다. 이는 기존에 구했던 1 -> 4 까지의 최단 거리인 5보다 크다. 어차피 1 -> 4 까지의 경로가 기존 경로보다 더 긴데, 그 이후 경로는 아무리 계산해도 최단 경로일 수 없는 것이다.
따라서 두 번째 경로를 확인하는 과정에서 4번 노드까지의 경로가 더 긴 경로임을 알아냈으니, 뒤의 6 -> ... -> 100의 경로는 계산이 무의미하므로 생략하여 시간을 아낄 수 있는 것이다.
이 로직은 전체 코드의 다음 구문을 통해 구현하였다.
while hq:
now_dis, now_v = heapq.heappop(hq)
# 가지치기
if now_dis > distance[now_v]:
continue
for next_v in graph[now_v]:
cost = next_v[0] + distance[now_v]
if cost < distance[next_v[1]]:
distance[next_v[1]] = next_v[0] + distance[now_v]
heapq.heappush(hq, [cost, next_v[1]])
현재 방문한 노드까지 경로의 누적 거리가, 지금까지 구해 놓은 방문 노드까지의 최단 거리보다 길다면 뒤 연산은 생략하는 것이다.
출력 예제
4주의할 점
다익스트라 알고리즘 개념에 더해, 시간 제한을 보고 어떻게 가지치기를 해야할지 알아낼 수 있어야 한다.
전체 코드
# 1916
import heapq
import sys
input = sys.stdin.readline
def dijkstra(start_v):
distance[start_v] = 0
hq = []
heapq.heappush(hq, [0, start_v])
while hq:
now_dis, now_v = heapq.heappop(hq)
# 가지치기
if now_dis > distance[now_v]:
continue
for next_v in graph[now_v]:
cost = next_v[0] + distance[now_v]
if cost < distance[next_v[1]]:
distance[next_v[1]] = next_v[0] + distance[now_v]
heapq.heappush(hq, [cost, next_v[1]])
if __name__ == "__main__":
INF = 100000 * 1000 + 1
N = int(input())
M = int(input())
graph = [[] for _ in range(N + 1)]
for _ in range(M):
v1, v2, c = map(int, input().split())
graph[v1].append([c, v2])
start, end = map(int, input().split())
distance = [INF] * (N + 1)
dijkstra(start)
print(distance[end])풀이 후기
다익스트라 알고리즘은 전공 과정의 컴퓨터 네트워크에서 두 엔드포인트 사이에 여러 라우터와 경로가 존재할 때, 두 엔드포인터끼리의 최단 거리를 구하는 부분에서 처음 접했던 개념이다.
그 당시에는 우선순위 큐를 사용하지 않고 구현을 하였었는데, 이번 포스팅과 문제 풀이를 계기로 우선순위 큐를 활용하여 더 효율적인 다익스트라를 공부할 수 있게 되어 유익한 시간이었다.
'알고리즘' 카테고리의 다른 글
| [알고리즘] 위상 정렬(Topological Sort) [ 백준 2252번 - 줄 세우기 ] (0) | 2024.11.26 |
|---|---|
| [알고리즘] 패턴 매칭 알고리즘, KMP 알고리즘 ( Knuth–Morris–Pratt Algorithm ) (6) | 2024.10.10 |
| [알고리즘] 0-1 Knapsack Problem (0-1 냅색 문제)[SWEA 3282번 - 0/1 Knapsack] (2) | 2024.05.16 |
| [알고리즘] LIS(최장 증가 부분 수열), 응용 문제 3가지 (0) | 2024.04.16 |
| [알고리즘] 플로이드-워셜(Floyd-Warshall) 알고리즘 [백준 11404번 - 플로이드] (2) | 2023.10.27 |



